Play all audios:
ABSTRACT To solve the problem of missed and false detection caused by the large number of tiny targets and complex background textures in a printed circuit board (PCB), we propose a global
contextual attention augmented YOLO model with ConvMixer prediction heads (GCC-YOLO). In this study, we apply a high-resolution feature layer (P2) to gain more details and positional
information of small targets. Moreover, in order to suppress the background noisy information and further enhance the feature extraction capability, a global contextual attention module (GC)
is introduced in the backbone network and combined with a C3 module. Furthermore, in order to reduce the loss of shallow feature information due to the deepening of network layers, a
bi-directional weighted feature pyramid (BiFPN) feature fusion structure is introduced. Finally, a ConvMixer module is introduced and combined with the C3 module to create a new prediction
head, which improves the small target detection capability of the model while reducing the parameters. Test results on the PCB dataset show that GCC-YOLO improved the Precision, Recall,
[email protected], and [email protected]:0.95 by 0.2%, 1.8%, 0.5%, and 8.3%, respectively, compared to YOLOv5s; moreover, it has a smaller model volume and faster reasoning speed compared to other algorithms.
SIMILAR CONTENT BEING VIEWED BY OTHERS IMPROVED PRINTED CIRCUIT BOARD DEFECT DETECTION SCHEME Article Open access 18 January 2025 A NOVEL PCB SURFACE DEFECT DETECTION METHOD BASED ON
SEPARATED GLOBAL CONTEXT ATTENTION TO GUIDE RESIDUAL CONTEXT AGGREGATION Article Open access 20 March 2025 A NOVEL YOLOV5_ES BASED ON LIGHTWEIGHT SMALL OBJECT DETECTION HEAD FOR PCB SURFACE
DEFECT DETECTION Article Open access 10 October 2024 INTRODUCTION In applications such as the Internet of Things and artificial intelligence, PCB, as a key electronic device, plays a
decisive role in the stability of the entire application1. To meet the current market demand for more sophisticated and complex electronic circuits, PCBs are moving toward precision,
multiple layers, and miniaturization2,3. In the process of PCB manufacturing, circuit defects are one of the key factors leading to performance degradation. To ensure the quality of PCB
products, it is necessary to achieve fast and efficient defect detection during PCB production. There are many causes of PCB defects, such as soldering failure, manufacturing or storage
conditions, and human factors. During PCB production, there are six common defects: missing hole, mouse bite, open circuit, short, spur, and spurious copper. This paper mainly studies these
six defects. The characteristics of these defects are as follows: (1) PCB circuit designs are diverse, resulting in a complex background environment for PCB defects; (2) the defect area is
small, and the color is similar to the background, which increases the difficulty of detection; and (3) while there are many kinds of defects, their characteristics are similar, which makes
detection more difficult and prone to false detection and missed detection. These characteristics may lead to the following problems for PCB surface defect detection: (1) complex textures
lead to the difficulty of the foreground and background distinction (2) tiny size leads to the problem of difficult detection. Currently, to address the above issues in visual detection,
methods such as enhancing feature extraction, optimizing models, background modeling, data augmentation, multi-scale training, and attention mechanisms can be used to improve model
performance. For the detection of complex background texture interference and tiny targets on the surface of PCB, the following development stages have been experienced. Early PCB surface
defect detection methods mainly include manual inspection, functional testing, and online testing. However, manual inspection is prone to visual fatigue, reducing detection efficiency and
easily leading to misjudgment; the template cost of functional testing is high, and the detection cycle is long, which is not conducive to detecting various types of defects; and online
testing only detects PCB electrical function defects, and thus, its detection scope and ability are limited. In recent years, PCB defect detection technology has developed, and a new
detection method with automatic optical inspection as its core is becoming popular4. A PCB detection algorithm based on traditional imageology takes visual features such as texture, edge
contour, and contrast as input to identify defects. However, these methods mainly relies on local features in the image when separating complex backgrounds, such as Scale-invariant feature
transform (SIFT), Speeded Up Robust Feature (SURF), etc. Conversely, a PCB detection algorithm based on machine learning takes a large number of features obtained from visual image
processing and classifies them through a classifier, thus achieving automatic detection of PCB surface defects. Machine learning methods such as support vector machines (SVMs)5, decision
trees6, and random forests7 have been widely applied in PCB inspection, effectively improving the accuracy and efficiency of defect detection and enabling more types of defects to be
detected. However, it still relies on effective feature information extraction algorithms and still struggles with the problems of complex foreground and background segmentation and small
target detection on PCB surfaces. In recent years, with the development and application of deep learning in various fields, several experts and scholars have focused on applying deep
learning methods to the field of PCB surface defect detection. And by introducing new technologies such as candidate box generation8, feature pyramid networks9, and multi-scale detection10,
it is possible to solve to some extent the difficulties encountered in detecting small targets and complex texture interference on PCB surfaces. Currently, deep learning-based object
detection methods are mainly divided into one-stage methods and two-stage methods, according to the object localization manner. Two-stage object detection methods are mainly represented by
Fast-RCNN11, Faster-RCNN8, and DetectoRS12 algorithms. Representative works of one-stage object detection mainly include YOLO series, SSD13, EfficientDet14, anchor-based RetinaNet15,
CenterNet16, and anchor-free RepPoints17. Two-stage target detection algorithms have high recognition accuracy and are suitable for precise recognition scenarios; however, there are problems
such as complicated training steps, slow detection speed, and large model volume. Thus, they are not suitable for PCB surface defect detection in industrial scenarios with lightweight and
high-speed detection requirements. The one-stage algorithm eliminates tedious and time-consuming positioning operations and unifies the positioning and classification of detection objects
using one network. It simplifies the network framework and training steps, improves the reasoning speed, and meets detection requirements in terms of detection accuracy and speed. In the
one-stage target detection network, the YOLO series network has been widely used to various downstream tasks, and it has significant advantages over other models in terms of detection
accuracy, speed, and deployment. Therefore, this paper takes a one-stage object detection algorithm as the research direction, the YOLOv5s algorithm as a baseline model, research on methods
such as multi-scale feature fusion, attention mechanism, and small target feature extraction and designs GCC-YOLO to solve the problems of high difficulty in distinguishing between PCB
surface defects and background and small defect size leading to false detection and missed detection. The main contributions of this paper are given below. * 1. We combine shallow
high-resolution small target features and location information of the P2 layer with a BiFPN feature fusion path to better utilize shallow information, reduce shallow feature loss caused by
the increase in model depth, and improve the model's detection ability for small targets. * 2. We combine a GC module of the global context attention enhancement mechanism with a C3
module, thereby producing a new C3GC module. By enhancing the attention mechanism of the global context, this module can reduce the noise interference caused by shallow features and
strengthen the feature extraction ability and anti-noise ability of the backbone network. * 3. We introduce a ConvMixer module with large kernel depth separable convolution and pointwise
convolution and combine it with the C3 module. A novel C3CM prediction head is designed to improve the receptive field of the prediction head and to enhance the model's ability to
detect small targets while maintaining the model's light weight. The rest of this paper is organized as follows. "Related work" section introduces related work on PCB surface
defect detection. "Methodology" section details the proposed method in this article. "Experiment" section reports experimental data, experimental procedures, experimental
results, and analysis of experimental results. Finally, in "Conclusion" section, we further summarize and analyze the proposed method in this article and consider further work.
RELATED WORK In this section, we first briefly review the related works of applying traditional visual algorithms, machine learning algorithms, and deep learning algorithms to PCB surface
detection and analyze the advantages and disadvantages of each stage of PCB automatic detection. Second, we introduce the detection performance of the model proposed in this paper. In the
research on traditional visual inspection algorithms for PCB detection, Gaidhane et al.18 proposed an efficient similarity measurement method for detecting and localizing local defects in
complex component-mounted PCB images. The proposed method is effective in detecting and locating local defects in complex component-mounted PCB images. Tsai et al.19 proposed a global
Fourier image reconstruction method to detect and locate PCB surface defects, and it could adapt to translation and illumination transformation environments. Abdel-Aziz Hassanin et al.20
proposed a real-time PCB automatic defect detection method based on SURF features and morphological operations, and it could accurately determine the fault location and fault type. Although
traditional detection algorithms based on image processing have certain detection effects, this type of detection method often has strict application conditions and cannot meet industrial
needs in terms of robustness and real-time performance. In the research on machine learning-based PCB detection algorithms, Tsai et al.21 proposed two entropy measures, i.e., color and
structure, and input them to an SVM classifier for automatic defect detection of PCB edge connectors. The proposed method was effective and efficient for detecting defects such as pinholes,
copper exposure, scratches, and roughness on gold-plated surfaces. Lu et al.22 proposed a PCB defect detection framework based on Bayesian feature fusion; it achieved good results in terms
of speed and accuracy, even for scenes such as those with uneven lighting and camera angle tilt. Thanasis Vafeiadis et al.23 proposed a framework for detecting PCB surface defects and
inferring failures of excessive or insufficient glue, with SVM as the optimal classifier. Although target detection algorithms based on machine learning have overcome the shortcoming of poor
robustness of traditional detection algorithms to a certain extent, they still face problems such as large data volume, redundant information, and high-dimensional feature space. Moreover,
they are easily affected by factors such as environment, light, production process, and noise. Regarding research on PCB detection algorithms based on a two-stage object detection network,
Hu et al.24 proposed an improved Faster RCNN algorithm based on the feature pyramid network ResNet50, thus improving the detection ability of small defects in PCBs. Meanwhile, Zeng et al.25
proposed an enhanced multi-scale feature fusion algorithm based on the asymmetric balanced feature pyramid network (ABFPN) and realized effective small target detection. Zhang et al.26
proposed the Cost-Sensitive Residual Convolutional Neural Network (CS-ResNet), which effectively balances the different misclassification costs of sample imbalance and real and false defects
in PCB detection. Two-stage object detection algorithms have high recognition accuracy and are suitable for precise recognition scenarios but face problems such as complicated training
steps, slow detection speed, and large model volume. Therefore, they are not suitable for PCB surface defect detection in industrial scenarios with lightweight and high-speed detection
requirements. To solve the problems of two-stage object detection methods, researchers proposed one-stage object detection algorithms, which eliminate the time-consuming localization
operations and unify the localization and classification of the detection objects into one network, thus simplifying the network framework and training steps and improving inference speed.
For instance, Kang et al.27 proposed an improved multi-layer SSD algorithm that addresses the false detection problem in PCB defect detection to some extent. Chen et al.28 proposed an
improved EfficientDet algorithm with parallel convolution modules, serial convolution modules, and feature fusion modules and achieved significant performance in detecting small defects.
Bhattacharya et al.29 proposed an improved YOLOv5 algorithm based on a Transformer backbone, which reduced the parameters of YOLOv5 while maintaining good detection accuracy. Overall, the
one-stage object detection algorithm maintains a fast detection speed and good detection accuracy but performs poorly in high-precision small target detection. Based on the problems of the
above algorithm, in order to improve the accuracy of PCB surface defect recognition and detection speed while meeting the requirements of lightweight deployment, this paper takes a one-stage
object detection algorithm as the research direction, the YOLOv5s algorithm as a baseline model, and proposes an improved GCC-YOLO algorithm. The proposed algorithm deals with a large
number of small targets and complex background noise interference on the PCB surface. This algorithm achieves 98.2% [email protected], 76.7% [email protected]:0.95, 68.0 FPS, and 14.5 Mb model size on the PCB
dataset, which verifies its effectiveness. METHODOLOGY To address the small size of surface defects on PCB, high similarity between defects and the background, and low distinction between
different types of defects, this paper proposes a global context attention enhancement and improved ConvMixer prediction head YOLO (GCC-YOLO) based on YOLOv5s. In this section, the basic
framework of YOLOv5s is introduced first. This is followed by a detailed description of the overall framework and four specific improvements brought by the proposed method. REVIEW OF YOLOV5
YOLO is a series of object detection algorithms based on deep learning and convolutional neural network. There are four models of YOLOv5, i.e., YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x, with
increasing depth and width of the network in that order. This paper chooses YOLOv5s as a baseline model and uses the pre-trained weights based on the COCO dataset for transfer learning to
establish a PCB surface defect detection algorithm. The YOLOv5s model consists of four main parts: the input, backbone, neck, and head. The input network uses Mosaic data augmentation,
randomly combining four images each time to increase the diversity of the dataset. The backbone network is used to extract image features and consists mainly of a C3 module and an SPP
module. The C3 module is composed of a bottle-neck structure and convolution layers, which accelerates the inference process. The SPP module uses three pooling kernels with sizes of 5, 9,
and 13 to perform maximum pooling on the input image, which greatly enhances the receptive field of the network. The neck is the fusion part of the network, and it adopts a combination of
feature pyramid networks (FPNs)9 and pyramid attention networks (PANs)30. It can effectively enhance the fusion effect of features of different scales. Finally, the head is the prediction
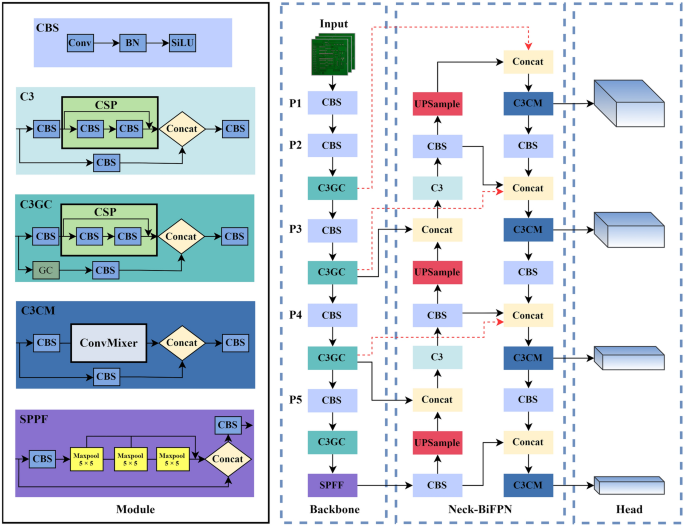
part of the network, and it outputs three vectors containing the predicted box class, confidence, and coordinate location. IMPROVED NETWORK ARCHITECTURE The framework of the GCC-YOLO
proposed in this paper is shown in Fig. 1. The main improvements of GCC-YOLO are as follows. (1) To fully utilize the position and detail information of small targets provided by the shallow
feature layer, a new feature fusion layer and a prediction head are added to the neck network to enhance the detection ability of small targets and make the network adapt to scale changes
of different types of defects on the PCB surface; (2) To extract more effective feature information, a global context attention enhancement (GC) module is introduced and combined with a C3
module, thus producing a new C3GC module. By making full use of global context information, this module can improve the ability to distinguish between defect areas and complex backgrounds,
reduce noise interference caused by shallow features, and enhance the feature extraction and anti-noise capabilities of the backbone network; (3) We introduce a bidirectional weighted
feature pyramid (BiFPN) feature fusion structure in the neck network to reduce the loss of shallow information and improve model accuracy; (4) We introduce a ConvMixer module with large
kernel depth separable convolution and pointwise convolution and combine it with the C3 module. A novel C3CM prediction head is designed to improve the receptive field of the prediction head
and to enhance the model's ability to detect small targets while maintaining the model's light weight. HIGH-RESOLUTION FEATURE LAYER P2 The existing small target definition
methods are mainly divided into the following two categories: relative scale-based definitions and absolute scale-based definitions. In a study on relative scale-based definitions, Chen et
al.31 proposed that the median of the ratio of the area of the bounding box to the area of the image in the same category is between 0.08 and 0.58%, which is considered as small targets. In
a study based on the absolute scale definition, Torralba et al.32 defined small targets as targets with a resolution of less than 32 × 32 pixels. When extracting features in convolutional
neural networks, due to the small pixel ratio of the target object, the feature information will gradually decrease after several down-sampling layers, and will continue to be lost as the
network level deepens33. The backbone network of YOLOv5s adopts an FPN structure, which continuously extracts features through three down-sampling layers and outputs down-sampled feature
maps p3, p4, and p5 of 1/8, 1/16, and 1/32 sizes of the original image, respectively. A 1/8 size version of the P3 feature map is used as input to the neck network for feature fusion for
small target detection. However, there are a large number of small targets in the PCB dataset, as shown in Table 1. We notice that there is a certain proportion of tiny targets with a size
less than 10 × 10 pixels, for which the target features become very weak or even disappear completely in the feature map after 1/8 down-sampling. Therefore, a shallow high-resolution feature
map P2 with 1/4 down-sampling is introduced into the backbone network, as shown in Fig. 2. In response, an F2 layer and a D2 layer are added to the neck network for feature fusion and micro
target prediction, respectively. ENHANCED BACKBONE WITH GLOBAL CONTEXTUAL ATTENTION Due to the high similarity between target defects and the background in the PCB dataset, noise
interference is common. Moreover, the introduced shallow feature map also carries a large amount of background information, if it is directly transmitted to the neck network without
effective processing, it will inevitably cause the feature information of small targets to be overwhelmed by background noise, which in turn affects the detection accuracy of small targets.
For the above problems, we notice that strengthening the extraction of global context information can simultaneously suppress background noise and enhance the feature information extraction
ability of small targets. Therefore, we introduce a global contextual attention module (GC)34, as shown in Fig. 3a. The GC module consists of context modeling, a bottleneck transform, and
broadcast element-wise addition. In the backbone network, the C3 module contains two feature propagation paths (see Fig. 3b). The first feature propagation path is fed into the CSP Block35
containing the residual connections after a 1 × 1 convolution, while the second feature propagation path fuses the features of these two feature propagation paths after a 1 × 1 convolution
to process the number of channels. However, in the second feature propagation path, there is a lot of unprocessed original information, which will lead to a lot of noise interference during
feature fusion. Therefore, the GC module is introduced in the second feature processing path to build a C3GC module with global context attention enhancement, which can well solve the
problems of background noise interference and small target information loss. The C3GC module is shown in Fig. 3c. Replacing all C3 modules in the backbone network with C3GC modules results
in the model retaining more small target feature details during each down-sampling (see Fig. 3d). This also, to some extent, weakens the shallow noise interference brought by the P2 layer,
which is beneficial for the detection of tiny defects in PCB. FEATURE FUSION YOLOv5s’ neck network uses a combined structure of an FPN and PAN and fuses the features of shallow feature
layers and deep feature layers (see Fig. 4b). The FPN can transfer deep semantic information to shallow layers without affecting the positional information, while the PAN can transfer the
positional information contained in the shallow feature layer to the deep feature layer. This combination effectively improves accuracy in network feature fusion, but it also brings some
problems. All the inputs of the PAN are feature information processed by the FPN and thus lack the original feature information of the trunk feature extraction network; this makes it easy to
cause bias in training and learning and thus affects the accuracy of detection. EfficientDet15 uses a BiFPN feature fusion structure that effectively fuses shallow feature information of
the backbone network and can well solve the problem of shallow feature loss. Hence, we replace the PANet feature fusion path in the original network architecture with BiFPN and remodel the
feature fusion path of YOLOv5s neck network, as shown in Fig. 4, for FPN, PANet, and BiFPN structures. CONVMIXER PREDICTION HEAD In YOLOv5s, the prediction head adopts a C3 module as the
general object detection head; but this is not specifically designed for small targets. Following its widespread application in the field of computer vision, the Transformer36 algorithm has
become another mainstream architecture after the RNN and CNN. Studying efficient attention architectures based on Transformer, Xingkui Zhu et al.37 proposed a TPH-YOLO algorithm by
introducing Transformer as the prediction head; they achieved high accuracy on small target detection on a drone target detection set, proving that the prediction head of YOLOv5s has
shortcomings in detecting small targets. In subsequent studies, ConvMixer38 achieved performance comparable to Vision Transformer with fewer resources by mixing data spatially and
channel-wise. This paper introduces a ConvMixer architecture as a new prediction head to improve the detection of small targets. In ConvMixer, the ConvMixer Layer is its core component, as
shown in Fig. 5a. It consists of depthwise separable convolution, pointwise convolution, a GELU activation function, and a BN, with a residual connection in one of the groups. The depthwise
separable convolution uses a 9 × 9 kernel design to ensure a larger field of view, and the pointwise convolution can enhance the detection of tiny targets. We combine the ConvMixer Layer
with the C3 module to replace the CSP structure in the original C3 module and thus form a new C3CM module to replace the prediction head in YOLOv5s (see Fig. 5b). The new detection head
brings a larger field of view to improve the model's detection and recognition capabilities. EXPERIMENT EXPERIMENTAL DATA The dataset adopted in our experiment is the PCB defect
dataset39 released by the Open Lab of Peking University; its defect types include missing hole (Mh), mouse bite (Mb), open circuit (Oc), short (Sh), spur (Sp), and spurious copper (Sc), and
it contains a total of 693 images. Examples of the six types of defects are shown in Fig. 6. To restore complex situations that may occur during automatic PCB inspection, the original
dataset is enhanced through image enhancement algorithms such as motion blur, random zooming, cropping, random light and dark, salt and pepper noise, and random rotation. An enhanced image
is shown in Fig. 7. After enhancement, the dataset is expanded to 4158 images. The distribution of various defects and instances in the dataset is shown in Table 1. The training set,
validation set, and test set are divided in the ratio of 8:1:1, with 3326 images in the training set and 416 images in both the test set and validation set. EXPERIMENTAL ENVIRONMENT AND
TRAINING PARAMETERS This experiment is built on an AutoDL server, with an RTX3090 GPU, Intel(R)Xeon(R)Platinum8358P CPU, running on a Linux operating system, using PyTorch1.8.1, Python3.8,
and CUDA11. The experimental environment was set up as shown in Table 2. To train our models, the Stochastic Gradient Descent (SGD) optimizer was used with a momentum and weight decay of
0.937 and 0.0005, respectively. And the learning rate was adjusted as 0.01. To find the optimal hyperparameter values, we chose image size 640 × 640, batch size 32, and the model was run for
up to 300 epochs. The training parameters are shown in Table 3. In order to prevent overfitting and enhance the generalization of the model, we have made reasonable adjustments to the data
augmentation parameters during training. Data augmentation can generate additional training samples by modifying existing training data or creating synthetic data. We used classic methods
such as image HSV enhancement, random scale sampling, random flip and mosaic enhancement. The Image augmentation hyperparameters are shown in Table 4. It is worth mentioning that when using
mosaic enhancement, 4 images are read for each training, and a series of operations such as random scaling, flipping, cropping, and optical transformation are performed again, then these
four images are stitched together, and the adjusted labels are passed into the network. This operation greatly enhances the diversity of training data and improves the model's ability
to detect small targets. The example images mosaic enhancement is shown in Fig. 8. EVALUATION METRICS To evaluate the overall performance of the model, the evaluation metrics used in this
experiment are precision (P), recall (R), average precision (AP), mean average precision (mAP), FPS, and model size. Their calculations are shown in Eqs. (1) – (5). Precision represents the
proportion of positive samples in the positive samples and is calculated as follows: $$\mathrm{Precision}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}}$$ (1) Recall indicates the proportion of
the predicted positive samples in the whole sample to the number of positive samples, and it is calculated as follows: $$\mathrm{Recall}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}$$ (2)
The F1-Score represents the weighted average of precision and recall, and it is calculated as follows: $$ {\text{F}}1 = \left( {\frac{2}{{ {\text{Recall}} ^{ - 1} + {\text{Precision}} ^{ -
1} }}} \right) = 2 \cdot \frac{{{\text{Precision}} \cdot {\text{ Recall}} }}{{ {\text{Precision}} + {\text{Recall}}}} $$ (3) The formulas for calculating AP and mAP are as follows:
$$\mathrm{AP}={\int }_{0}^{1}\mathrm{P}(\mathrm{R})\mathrm{dR}$$ (4) $$\mathrm{mAP}=\frac{{\Sigma }_{\mathrm{j}=1}^{\mathrm{S}}\mathrm{AP}\left(\mathrm{j}\right)}{\mathrm{S}}$$ (5) In the
above equation, S represents the number of all categories and is both the denominator and the sum of the AP of all categories. EXPERIMENTAL RESULTS AND ANALYSIS To verify the effectiveness
of the various new modules proposed in this paper, an ablation experiment scheme is designed, as shown in Table 5. Scheme 1 is YOLOv5s; Scheme 2 is introducing the shallow high-resolution
layer P2; Scheme 3 is adding the C3GC module in the backbone network and is based on Scheme 2; Scheme 4 is introducing the BiFPN feature fusion path and is based on Scheme 3; and Scheme 5 is
adding the C3CM module as the detection head in the neck network and is based on Scheme 4. The ablation experiment results of the five schemes are shown in Table 6. Below, we discuss each
observed improvement. In addition, we visualized the training loss and performance metrics of YOLOv5 and the improved GCC-YOLO, as shown in Figs. 9 and 10, respectively, to verify the
performance and generalization performance of the improved model. INFLUENCE OF HIGH-RESOLUTION FEATURE LAYER P2 According to the results of Scheme 2 in Table 6, after adding the P2 layer,
the recall rate increased by 1% and [email protected]:0.95 increased by 4.9%. This indicates that by adding the P2 layer, the detailed information and localization information of shallow small targets
can be extracted effectively, which helps to prevent missed detections. INFLUENCE OF IMPROVED BACKBONE The results of Scheme 3 in Table 6 show that by introducing global contextual
attention enhancement to extract the C3GC module on the backbone network, the interference caused by shallow background noise can be effectively reduced, thus avoiding invalid feature
propagation and making the model pay more attention to the effective area. Compared to Scheme 2, the introduction of C3GC resulted in a slight decrease in recall rate, while other indicators
increased. INFLUENCE OF FEATURE FUSION According to the results of Scheme 4 in Table 6, by introducing the BiFPN feature fusion path in the neck network, the shallow layer feature
information of the jump connection backbone network is relieved, which reduces feature information loss when the shallow layer small target features are propagated in the network. Compared
with Scheme 3, the detection precision for mouse bite and open circuit when there are many small targets is increased by 0.4% and 0.1%, respectively. However, we note that the fusion of too
many shallow feature information also brings certain optimization problems, i.e., the detection precision of both the relatively large-sized short and spur defect type decreased by 0.1%, and
the recall rate of the model decreased by 0.1%. INFLUENCE OF CONVMIXER PREDICTION HEADS According to the results of Scheme 5 in Table 6, the introduction of the C3CM prediction head with a
large field of view and pointwise convolution improves the recall rate and detection precision for small targets. Compared to Scheme 4, the model recall rate and [email protected]:0.95 increases by 1%
and 1.1%, respectively. SUMMARY OF MODEL IMPROVEMENT PERFORMANCE The loss function of YOLO model includes box loss, objectness loss, and classification loss. Box loss evaluates the
algorithm's ability to accurately locate the center and boundary box of the object, objectness loss quantifies the likelihood of finding an object within a given region, and
classification loss represents the accuracy of the algorithm in determining the correct category of the object. As shown in Fig. 9, GCC-YOLO has a faster convergence speed and a smoother
loss curve compared to the baseline model YOLOv5, this indicates that GCC-YOLO achieved better performance during training and has better generalization ability. As shown in Fig. 10,
compared with YOLOv5, GCC-YOLO has better performance in [email protected], [email protected]:0.95, precision and recall, this indicates that the improved model can better detect small defects on the surface of
PCB and has better detection accuracy. COMPARISON OF ALGORITHMS To evaluate the detection performance of GCC-YOLO for tiny targets under complex texture interference, we first selected
three advanced models40,41,42 that perform well in small object detection in the PCB dataset, as well as TPH-YOLO37 which has achieved outstanding results in small object detection in
unmanned aerial vehicles, for comparative experiments. The experimental results of the five algorithms on the enhanced PCB dataset are shown in Table 7. Secondly, we compared the performance
of GCC-YOLO with Faster R-CNN8, RetinaNet15, CenterNet16, YOLOv343, YOLOv5, YOLOv8 and other adcanved target detection models, the comparison experimental data are shown in Table 8, and the
detection results are shown in Fig. 11. In addition, we also compared the stability and complexity of GCC-YOLO with other YOLO models, and the results are shown in Table 9, because the
lightweight model volume and lower model complexity are of great significance for the rapid deployment of PCB. ANALYSIS BETWEEN GCC-YOLO AND OTHER ADVANCED PCB DEFECT DETECTION ALGORITHMS
According to the experimental results shown in Table 8, compared with other small target detection models, GCC-YOLO achieved the best Recall value of 97.3% in the enhanced PCB dataset, this
shows that GCC-YOLO can effectively locate more small targets, and achieved the best detection accuracy in almost all types, except the mouse bite type, this demonstrates that GCC-YOLO has
excellent performance in detecting small targets. ANALYSIS BETWEEN GCC-YOLO AND OTHER ADVANCED OBJECT DETECTION ALGORITHMS According to the detection results shown in Fig. 11, Faster R-CNN
has the worst performance on the PCB dataset, with four missed detections and one false detection. The other algorithms also have missed detections, i.e., one for RetinaNet, four for YOLOv3
and YOLOv5s, three for YOLOv5s, and one for YOLOv8. These are mainly mouse bite and spur. Only GCC-YOLO correctly detects all the defect targets. The comparison experiment results show that
GCC-YOLO effectively improves the detection precision for various types of defects compared to several mainstream models. The AP values for missing hole, mouse bite and open circuit are
99.5%, 98.3%, and 98.6%, respectively; these are all better than those of the other algorithms. In terms of model performance, the [email protected] and [email protected]:0.95 values of GCC-YOLO reach 98.2% and
76.7%, respectively. Compared to the original YOLOv5s, these are increases of 0.5% and 8.3%, respectively. Compared to the latest YOLOv8 algorithm, [email protected] is increased by 0.6%. In terms of
detection speed, GCC-YOLO achieves 68.0 FPS, comparing with Faster R-CNN 12.0 FPS, RetinaNet 12.9FPS, CenterNet 6.9 FPS, and YOLOv3 59.9 FPS; this makes GCC-YOLO more adaptable to
industrial scenarios. Model stability and complexity of YOLO Series are compared in Table 6. The detection precision, recall rate, and F1-Score of GCC-YOLO reach 99.0%, 97.3%, and 98.1%,
respectively, outperforming the other algorithms. Thus, GCC-YOLO has the highest stability. The results of the complexity comparison experiment show that the parameters, GFLOPS, and model
size of GCC-YOLO are 6,874,836, 17.8G, and 14.5 Mb, respectively. among which the parameters are the least compared with other networks, which is due to ConvMixer with depthwise convolution
replacing the CSP structure in the original C3 module. GFLOPS is slightly increased in the proposed model compared to YOLOv5s but is lower than those of YOLOv3 and YOLOv8; hence, the
improvements made in this paper do not significantly increase the complexity of the model. Finally, the model size is lower than 117 mb and 21.4 mb for YOLOv3 and YOLOv8, respectively, thus
indicating that GCC-YOLO is a lightweight model suitable for the industrial needs of PCB lightweight detection. CONCLUSION This paper proposes the GCC-YOLO model, which improves on the
YOLOv5s network structure to address the challenge of detecting small targets on the PCB dataset. First, a shallow high-resolution P2 layer is introduced to avoid the problem of losing small
target feature information due to excessive down-sampling. Second, introducing a feature extraction module with global contextual attention enhancement into the backbone network suppresses
the background noise interference caused by shallow features and makes the model pay more attention to the target area. Then, introducing a BiFPN feature fusion path to replace the original
PANet structure in the neck network reduces shallow feature loss due to the increase in model depth. Finally, introducing a lightweight prediction head with a large field of view further
enhances the model's ability to detect small targets. Experimental results show that GCC-YOLO outperforms other mainstream object detection models on the PCB dataset in terms of
overcoming the problems of false detection and missed detection. Furthermore, it has better detection precision and detection speed while also meeting the requirements of lightweight
deployment. Therefore, it meets the industrial requirements of PCB surface defect detection. In our current work, we have done a lot of design work for small target PCB surface defects with
our model. However, the detection precision for the relatively large-sized spurious copper type defect has a lower precision value, and in each ablation experiment, it was at the relatively
lowest detection accuracy. According to experimental data, the detection accuracy of spurious copper has continuously decreased after introducing the P2 layer and C3GC module. Large-scale
experiments have shown that incorporating more large-scale feature map information is beneficial for detecting small targets, but does not provide any benefits for relatively large spurious
copper defects in terms of size. And the fusion of shallow feature maps brings more noise interference. Meanwhile, the introduction of the C3GC module with anti-texture feature extraction
ability may over-process these interferences, which affects the deeper feature information of the backbone network and thus affects the detection accuracy of relatively larger scale defects.
Regarding the above issues, relevant studies have shown that improvements can be made from the following perspectives: (1) Introducing candidate box generation algorithms with adaptive
adjustment can generate more fitting candidate boxes to improve the detection accuracy of a certain scale feature; (2) Introducing multi-scale feature fusion path with dynamic adjustment to
balance the detection accuracy problem of different scales; (3) Introducing anchor-free mechanism and decoupling head network can also balance the problem of detection accuracy imbalance
among different categories without generating candidate boxes and separating classification and positioning calculations. In the future, our subsequent work will continue the research from
these three aspects. DATA AVAILABILITY All data generated or analysed during this study are available in the Github repository. Links to the code and datasets are provided in the below
hyperlinked text. Code and dataset of GCC-YOLO project: https://github.com/2462954048/GCC-YOLO-V2/tree/master. REFERENCES * Ghosh, S., Sathiaseelan, M. A. M. & Asadizanjani, N. Deep
learning-based approaches for text recognition in PCB optical inspection: A survey. In _2021 IEEE Physical Assurance and Inspection of Electronics_ (PAINE), 1–8 (IEEE, 2021). * Goto, K. _et
al._ Adversarial autoencoder for detecting anomalies in soldered joints on printed circuit boards. _J. Electron. Imaging_ 29(4), 041013–041013 (2020). Article ADS Google Scholar * Huang,
L. _et al._ A novel multi-pattern solder joint simultaneous segmentation algorithm for PCB selective packaging systems. _Int. J. Pattern Recognit. Artif. Intell._ 33(13), 2058005 (2019).
Article Google Scholar * Ren, Z. _et al._ State of the art in defect detection based on machine vision. _Int. J. Precis. Eng. Manuf. Green Technol._ 9(2), 661–691 (2022). Article
MathSciNet Google Scholar * Pisner, D. A. & Schnyer, D. M. Support vector machine. In: _Machine Learning_. 101–121 (2020). * Kotsiantis, S. B. Decision trees: A recent overview.
_Artif. Intell. Rev._ 39, 261–283 (2013). Article Google Scholar * Biau, G. & Scornet, E. A random forest guided tour. _TEST_ 25, 197–227 (2016). Article MathSciNet MATH Google
Scholar * Ren, S., et al. Faster r-cnn: Towards real-time object detection with region proposal networks. _Adv Neural Inf. Process. Syst._ 28 (2015). * Lin, T. Y., et al. Feature pyramid
networks for object detection. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_, 2117–2125 (2017). * Cai, Z., et al. A unified multi-scale deep
convolutional neural network for fast object detection. In _European Conference on Computer Vision_, 354–370 (Springer, Cham, 2016). * Girshick, R. Fast r-cnn. In _Proceedings of the IEEE
international conference on computer vision_, 1440–1448 (2015). * Qiao, S., Chen, L.C. & Yuille, A. DetectoRS: Detecting objects with recursive fea-ture pyramid and switchable atrous
convolution. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ (CVPR), 10213–10224 (2021). * Liu, W., et al. Ssd: Single shot multibox detector. In
_European Conference on Computer Vision_, 21–37 (Springer, Cham, 2016). * Tan, M., Pang, R. & Le, Q. V. EfficientDet: Scalable and efficient object detection. In _Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition_ (CVPR), 10781–10790 (2020). * Zhang, S., Chi, C., Yao, Y., Lei, Z. & Li, S. Z. Bridging the gap between anchor-based and
anchor-free detection via adaptive training sample selection. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ (CVPR), 9759–9768 (2020). * Duan, K., et
al. Centernet: Keypoint triplets for object detection. In _Proceedings of the IEEE/CVF international conference on computer vision_ (ICCV), 6569–6578 (2019) * Yang, Z., Liu, S., Hu, H.,
Wang, L. & Lin, S. RepPoints: Point set representation for object detection. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ (ICCV), 9657–9666 (2019). *
Gaidhane, V. H., Hote, Y. V. & Singh, V. An efficient similarity measure approach for PCB surface defect detection. _Pattern Anal. Appl._ 21, 277–289 (2018). Article MathSciNet Google
Scholar * Tsai, D. M. & Huang, C. K. Defect detection in electronic surfaces using template-based fourier image reconstruction. _IEEE Trans. Compon. Packag. Manuf. Technol._ 9(1),
163–172 (2018). Article Google Scholar * Hassanin, A. A. I. M., Abd El-Samie, F. E. & El Banby, G. M. A real-time approach for automatic defect detection from PCBs based on SURF
features and morphological operations. _Multimed. Tools Appl._ 78, 34437–34457 (2019). Article Google Scholar * Tsai, D. M. & Lin, B. T. Defect detection of gold-plated surfaces on
PCBs using entropy measures. _Int. J. Adv. Manuf. Technol._ 20, 420–428 (2002). Article Google Scholar * Lu, Z. _et al._ Defect detection of PCB based on Bayes feature fusion. _J. Eng._
2018(16), 1741–1745 (2018). Article Google Scholar * Vafeiadis, T. _et al._ A framework for inspection of dies attachment on PCB utilizing machine learning techniques. _J. Manag. Anal._
5(2), 81–94 (2018). Google Scholar * Hu, B. & Wang, J. Detection of PCB surface defects with improved faster-RCNN and feature pyramid network. _IEEE Access_ 8, 108335–108345 (2020).
Article Google Scholar * Zeng, N. _et al._ A small-sized object detection oriented multi-scale feature fusion approach with application to defect detection. _IEEE Trans. Instrum. Meas._
71, 1–14 (2022). Google Scholar * Zhang, H., Jiang, L. & Li, C. CS-ResNet: Cost-sensitive residual convolutional neural network for PCB cosmetic defect detection. _Expert Syst. Appl._
185, 115673 (2021). Article Google Scholar * Kang, L., et al. Research on PCB defect detection based on SSD. In _2022 IEEE 4th International Conference on Civil Aviation Safety and
Information Technology_ (ICCASIT), 1315–1319 (IEEE, 2022). * Chen, G. _et al._ ESDDNet: Efficient small defect detection network of workpiece surface. _Meas. Sci. Technol._ 33(10), 105007
(2022). Article ADS Google Scholar * Bhattacharya, A. & Cloutier, S. G. End-to-end deep learning framework for printed circuit board manufacturing defect classification. _Sci. Rep._
12(1), 12559 (2022). Article ADS CAS PubMed PubMed Central Google Scholar * Liu, S., et al. Path aggregation network for instance segmentation. In _Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition_, 8759–8768 (2018). * Chen, C., et al. R-CNN for small object detection. In _Computer Vision_, 214–230 (Springer, Cham, 2016). * Torralba, A.,
Fergus, R. & Freeman, W. T. 80 million tiny images: A large data set for nonparametric object and scene recognition. _IEEE Trans. Pattern Anal. Mach. Intell._ 30(11), 1958–1970 (2008).
Article PubMed Google Scholar * Shrivastava, A. & Gupta, A. Contextual priming and feedback for faster r-cnn. In _European Conference on Computer Vision_, 330–348 (Springer, Cham,
2016). * Cao, Y., et al. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. _In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops_, 0–0
(2019). * Wang, C. Y., et al. CSPNet: A new backbone that can enhance learning capability of CNN. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Workshops_ (CVPR), 390–391 (2020). * Vaswani, A., et al. Attention is all you need. _Adv. Neural Inf. Process. Syst._ 30 (2017). * Zhu, X., et al. TPH-YOLOv5: Improved YOLOv5 based on
transformer prediction head for object detection on drone-captured scenarios. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ (ICCV), 2778–2788 (2021). *
Trockman, A., Kolter, J. Z. Patches are all you need? arXiv preprint arXiv:2201.09792, (2022). * Ding, R. _et al._ TDD-net: A tiny defect detection network for printed circuit boards. _CAAI
Trans. Intell. Technol._ 4(2), 110–116 (2019). Article Google Scholar * Ye, M., Wang, H. & Xiao, H. Light-YOLOv5: A lightweight algorithm for improved YOLOv5 in PCB defect detection.
In 2023 IEEE 2nd _International Conference on Electrical Engineering, Big Data and Algorithms_ (EEBDA), 523–528 (IEEE, 2023). * Liang, M., Wu, J. & Cao, H. Research on PCB small target
defect detection based on improved YOLOv5. In 2022 International Conference on Sensing, Measurement & Data Analytics in the era of Artificial Intelligence (ICSMD), 1–5 (IEEE, 2022). *
Tang, J. _et al._ PCB-YOLO: An improved detection algorithm of PCB surface defects based on YOLOv5. _Sustainability._ 15(7), 5963 (2023). Article CAS Google Scholar * Redmon J, Farhadi A.
Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, (2018). Download references ACKNOWLEDGEMENTS This work was supported by the National Natural Science Foundation of China
(Grant No. 51705053), Chongqing Talents Program Innovation and Entrepreneurship Demonstration Team (Grant Nos. CQYC201903230, CSTC2021ycjh-bgzxm0346), Chongqing Research Program of Basic
Research and Frontier Technology (Grant Nos. CSTC2019jcyj-msxmX0720, CSTB2022nscq-LZX0052), Science and Technology Research Program of Chongqing Municipal Education Commission (Grant Nos.
KJZD-K201901503, KJZD-M202201501), and the Innovation Program for Master Students of Chongqing University of Science and Technology (Grant Nos. YKJCX2120317, YKJCX2220329, YKJCX2220325).
AUTHOR INFORMATION AUTHORS AND AFFILIATIONS * School of Mechanical and Power Engineering, Chongqing University of Science and Technology, Chongqing, 401331, China Kewen Xia, Zhongliang Lv,
Kang Liu, Zhenyu Lu, Chuande Zhou, Hong Zhu & Xuanlin Chen Authors * Kewen Xia View author publications You can also search for this author inPubMed Google Scholar * Zhongliang Lv View
author publications You can also search for this author inPubMed Google Scholar * Kang Liu View author publications You can also search for this author inPubMed Google Scholar * Zhenyu Lu
View author publications You can also search for this author inPubMed Google Scholar * Chuande Zhou View author publications You can also search for this author inPubMed Google Scholar *
Hong Zhu View author publications You can also search for this author inPubMed Google Scholar * Xuanlin Chen View author publications You can also search for this author inPubMed Google
Scholar CONTRIBUTIONS K.X. developed the experimental plan and methodology. K.X. and Zhongliang Lv developed the model and performed the experiments, C.Z. analyzed the experimental effect,
K.L. and Zhenyu Lu performed statistical analysis and figure generation, H.Z. and X.C. conducted the literature survey and data collection. All authors were involved in writing and reviewing
the manuscript. CORRESPONDING AUTHORS Correspondence to Zhongliang Lv or Chuande Zhou. ETHICS DECLARATIONS COMPETING INTERESTS The authors declare no competing interests. ADDITIONAL
INFORMATION PUBLISHER'S NOTE Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. RIGHTS AND PERMISSIONS OPEN ACCESS
This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as
long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third
party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the
article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the
copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. Reprints and permissions ABOUT THIS ARTICLE CITE THIS ARTICLE Xia, K., Lv, Z., Liu, K.
_et al._ Global contextual attention augmented YOLO with ConvMixer prediction heads for PCB surface defect detection. _Sci Rep_ 13, 9805 (2023). https://doi.org/10.1038/s41598-023-36854-2
Download citation * Received: 17 March 2023 * Accepted: 11 June 2023 * Published: 16 June 2023 * DOI: https://doi.org/10.1038/s41598-023-36854-2 SHARE THIS ARTICLE Anyone you share the
following link with will be able to read this content: Get shareable link Sorry, a shareable link is not currently available for this article. Copy to clipboard Provided by the Springer
Nature SharedIt content-sharing initiative