Play all audios:
ABSTRACT Forced alignment is a speech technique that can automatically align audio files with transcripts. With the help of forced alignment tools, annotating audio files and creating
annotated speech databases have become much more accessible and efficient. Researchers have recently started to evaluate the benefits and accuracy of forced aligners in speech research and
have provided insightful suggestions for improvement. However, current work has so far paid little attention to evaluating forced aligners in prosody research, which focuses on
suprasegmental features. In this paper, we take ambiguous sentence-level audio input in Mandarin Chinese, which can be disambiguated prosodically, to evaluate the alignment accuracy of the
Montreal Forced Aligner (MFA). With a satisfactory result for syllable-by-syllable alignment, we further explore the possibility and benefits of using the forced alignment tool to generate
phrase-by-phrase alignment. This topic has barely been studied in previous research on forced alignment. Our paper demonstrates that the forced alignment tool can effectively generate
accurate alignment at both syllable and phrase levels for tonal languages, such as Mandarin. We found that the average differences between human annotators and MFA were smaller than the gold
standard, indicating a satisfactory level of performance by the tool. Moreover, the MFA-assisted annotation rate by human transcribers was at least 20 times faster than previously reported
manual annotation efficiency, providing significant time and resource savings for prosody researchers. Our results also suggest that phrase-level alignment accuracy of MFA can be affected by
the quality of the recording, calling prosody researchers’ attention to controlling the audio quality in the recording. The finding that de-stressed words/phrases pose challenges for MFA
also provides a reference for improving forced aligners. SIMILAR CONTENT BEING VIEWED BY OTHERS JOINT SPEECH AND TEXT MACHINE TRANSLATION FOR UP TO 100 LANGUAGES Article Open access 15
January 2025 A DATASET OF REAL AND SYNTHETIC SPEECH IN UKRAINIAN Article Open access 06 May 2025 ASSESSING THE ACCURACY OF AUTOMATIC SPEECH RECOGNITION FOR PSYCHOTHERAPY Article Open access
03 June 2020 INTRODUCTION Speech research often requires detailed annotation on audio files to formulate statistical analysis about the information revealed by the sounds. Annotation tasks
include aligning phoneme, syllable, word, and phrase boundaries so that researchers can extract phonetic and phonological information such as the duration, pitch, and intensity of specific
regions of speech. Manual annotation of audio files is undoubtedly a tedious and resource-consuming task for speech researchers. Researchers need to listen to the audio repeatedly to label
and align the boundaries manually. A 1-min audio file may require hours of annotation work. Moreover, multiple annotators need to work on the same audio annotation and compare the
inter-annotator agreement to avoid human annotation errors. Fortunately, with the rapid development of speech recognition technology since the 1970s, forced alignment, as a technique to
align audio files and create auto-generated annotations, has evolved significantly, which makes automatic annotation possible and efficient. According to Pettarin (2018)’s collections, there
are at least 15 open resource programs. Research has reported highly positive feedback on the performance of forced alignment tools, especially on phoneme boundaries (DiCanio et al., 2013;
Hosom, 2009; Goldman, 2011; Gorman et al., 2011; Yuan and Liberman, 2015; Yuan et al., 2018; Yuan et al., 2014; McAuliffe et al., 2017; Sella, 2018; MacKenzie and Turton, 2020; Mahr et al.,
2021; McAuliffe, 2021; Liu and Sóskuthy, 2022). Combined with the easy accessibility of forced aligners in recent years, forced alignment has drawn increasing attention from speech
researchers and resulted in growing applications of forced aligners in speech research. In this study, we evaluated forced aligners from the perspective of prosodic research for tonal
languages, which has barely been discussed in the literature. Using a forced aligner in Mandarin prosodic analysis, we aim to provide an example of how to use forced alignment in speech
research that investigates suprasegmental-level sound information and how to measure the performance of forced aligners when applied to a tonal language such as Mandarin Chinese. THE TOOL
AND INPUT The purpose of this study was to evaluate the automatic alignment performances for speech prosody research. We chose the Montreal Forced Aligner as the forced aligner tool and
speech data collected from native adult speakers of Mandarin Chinese as the input. MONTREAL FORCED ALIGNER (MFA) MFA is an alignment tool with high accessibility and compatibility (McAuliffe
et al., 2017). It is open-source software with prebuilt executables for both Windows and Mac OSX. MFA has a pre-trained model for some languages, and it can be trained with other languages
that are not included in the model.Footnote 1 As an update of the Prosodylab-Aligner (Gorman et al., 2011), MFA uses more advanced acoustic models based on triphones and is built using the
Kaldi toolkit, offering “advantages over the HTK toolkit underlying most existing aligners” (McAuliffe et al., 2017). Recent research by Mahr et al. (2021) and Liu and Sóskuthy (2022) both
reported highly positive evaluation results on MFA. Mahr et al. (2021) evaluated the performances of popular forced alignment algorithms on children’s American English speech samples and
reported that the aligners’ accuracy ranges from 67 to 86%, compared to the gold-standard human annotation. Among the five forced aligners in their consideration, MFA with speaker-adaptive
training (McAuliffe et al., 2017) was the most accurate aligner across speech sound classes, with an average percentage accuracy of 86%. Liu and Sóskuthy (2022) evaluated the performances of
MFA on four Chinese varieties (Canto, Shanghai, Beijing, and Tianjin) and also found strong agreement between human and machine-aligned phone boundaries, with 17 ms as the median onset
displacement and little variation across the Chinese varieties. Based on reported evaluation results, MFA showed excellent performance in aligning word and phone boundaries in various speech
datasets (McAuliffe et al., 2017; McAuliffe, 2021) and produced higher quality alignments compared to other forced aligners (Gonzalez et al., 2020; Mahr et al., 2021). THE SPEECH DATASET
The dataset for the evaluation of MFA was established in the following way: A total of 33 adult speakers of Mandarin Chinese, aged 18 years or older, were recruited through social media and
contributed speech samples. Fifteen of them (eight females and seven males) recorded their speeches through their phones or laptops and submitted their recordings through emails; the other
18 (nine females and nine males) recorded their speeches in a sound-proof recording booth with professional recording equipment.Footnote 2 Speech samples were recorded based on given target
sentences. Fifty-six target sentences containing _wh_-words (e.g., _sh_é_nme_ ‘what’) were included in the stimuli, with the number of syllables in the sentences ranging from 7 to 20. The
target sentences varied in the position of the _wh_-word (i.e., subject or object) and the structure of the sentence (i.e., simple transitive sentences, simple ditransitive sentences,
sentences with conditional clauses, and sentences with their subject left-dislocated), as shown in Table 1. There were 24 unique sentences in Group 1, 8 unique sentences in Group 2, 8 unique
sentences in Group 3, and 16 unique sentences in Group 4. Each target sentence was potentially ambiguous (Table 1), and participants were provided with two or four possible interpretations
along with the target sentences. For each given meaning of the target sentence, participants were required to read out the target sentence if they thought it could be used to express that
meaning. Otherwise, they could choose to say, “I do not think the target sentence can be used to express the given meaning.” Participants were allowed to update their recording sample of a
sentence anytime by re-recording a sentence before submitting the audio files. After the data collection, to prepare for the audio format required by MFA, we converted all audio files into
WAV files using Praat (Boersma and Weenink, 2021) if they were in a different format. Since Kaldi (the toolkit that MFA was built on) can only process 16-bit files, MFA by default converts
audio files that have higher bit depths than 16-bit into 16-bit. MFA supports both mono and stereo files but by default samples the files with a higher or lower sampling rate than 16 kHz
into 16 kHz during the feature generation procedure; therefore, we did not take steps to normalize the sampling rates, bit depth and channels of all audio files. We then trimmed the audio
files so that only the speech on the target sentences of the experiment was kept. When there were multiple recordings of a target sentence, we only kept the last recording of the sentence in
the dataset. After chopping the long sound files into separate audio files by sentence, for each speaker, 128 recorded audio files were included in the dataset, with 48 audio files from
Group 1, 16 audio files from Group 2, 32 audio files from each of Group 3 and Group 4. One speaker’s submission (Speaker 5) was not included in the dataset due to incomplete recordings. In
total, we collected 4096 audio files from 33 speakers with the duration of audio files ranging from 1 s to 4 s, in total resulting in a 216-min-long speech dataset. We further coded the
audio files to identify the audio files that do not match the given target sentences, such as missing words, repeating words, paraphrasing words, and adding extra words. Each audio file was
coded with a label corresponding to the target sentence and specified reading, otherwise “null” if the speaker said “I do not think the target sentence can be used to express the given
meaning” or “misread” if the sentence that the speaker recorded did not match the target sentence. When generating MFA alignment and evaluating the MFA alignment results, audio files with
“null” or “misread” labels were excluded. Although it is not spontaneous speech data collected from a natural conversation environment, this dataset has three main advantages. First, it
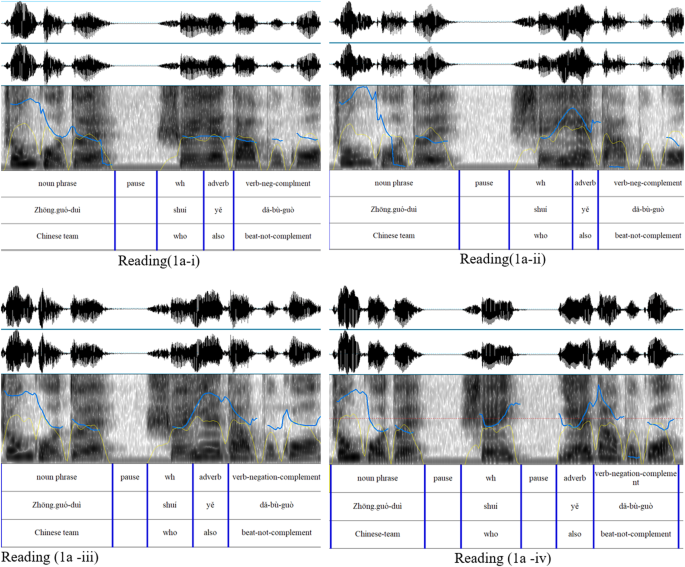
contains minimal pairs of naturally occurring ambiguous sentences that are prosodically distinguished. Take (1), a sentence from Group 3 as an example. (1) _Zhōng.guó-duì_ _shuí_ _yě_
_dǎ-bù-guò_ Chinese-team who also beat-not-complement a. _wh_-indefinite: (i) ‘The Chinese team can’t beat anyone.’ or (ii) ‘No one can beat the Chinese team.’ b.
_wh_-interrogative: (iii) ‘Who is the team that the Chinese team also can’t beat?’ or (iv)‘Who is the team that also can’t beat the Chinese team?’ Sentences like (1) are often used by
native speakers in social media to express (1a-i) when talking about the Chinese male soccer team losing all the games or to express (1a-ii) when talking about the Chinese ping-pong team
winning all the games. Wu and Yun (2022) found that sentences like (1) can also induce interrogative readings as in (1a-iii) and (1a-iv). It is important to note that the various readings of
(1) share the same underlying phonemic tones and syllables. However, these tones and syllables are realized with variations in order to achieve different readings. For example, the
_wh-_word “shuí” is typically associated with a rising tone. However, it is commonly realized with a neutral tone or a tone that only slightly rises in pitch when it refers to
_wh_-indefinite, as in (1a-i) and (1a-ii). Similarly, the adverb “yě” typically has a tone that falls before rising in pitch. Yet, in the _wh_-indefinite contexts, it is often produced with
a shorter duration and a tone that only partially falls before rising. The four readings of (1) can also be distinguished by the length of the pause between the noun phrase and the
_wh_-word, and between the _wh_-word and the adverb. Figure 1 displays an example of how these four meanings of (1) may be phonetically and prosodically different. Since the ambiguous
sentences share the same underlying phonemic tones for different meanings (i.e., same transcript and same dictionary input to MFA) but can nevertheless be realized with different phonetics
depending on the meaning, the data provide an excellent opportunity to evaluate how well MFA can handle some departure in production from the expected dictionary pronunciation of these
words. Second, the dataset contains sentence-level speech production with words that have a neutral tone and _er_-suffixation and thus can help evaluate whether the forced aligner can
correctly align sentences with various word types. The stimuli included words with neutral tones, such as the perfective marker _le_, in addition to words with the canonical four tones in
Mandarin. In most cases, one character corresponds to one syllable, but _er_-suffixation makes two characters correspond to one syllable. Words with neutral tones and _er_-suffixation are
often less salient in prosody and may make syllable boundaries less clear, which poses challenges for forced alignment. Third, it is a balanced dataset that has audio files from both lab
recordings and non-lab recordings, and a similar amount of audio files from both female and male speakers. Thus, it provides a potential way to evaluate if the audio input quality and gender
affect the alignment results. EVALUATIONS Using the audio data introduced in section “The tool and input” as input, we conducted forced alignment using MFA at two different levels:
syllable-by-syllable alignment and phrase-by-phrase alignment. Then we assessed each alignment result to evaluate the performance of MFA in terms of annotation accuracy and annotation speed.
SYLLABLE-BY-SYLLABLE ALIGNMENT ACCURACY MFA, like many other alignment tools, takes audio files (.wav), their accompanying transcript files, and a pronunciation dictionary (.txt) as input.
Since there was no ready-to-use MFA pronunciation dictionary for Mandarin in the MFA version 1.0 repository, we followed the format of the prepared Mandarin dictionary example in the MFA
tutorial guide and created a pinyin pronunciation dictionary for the alignment task (Table 2). Considering that one Chinese character corresponds to one syllable, we used _Xiàndài Hànyǔ
Chángyòngzì Biǎo_ ‘_3500 commonly used Chinese characters_’, published by the Ministry of Education in China in 1988, to create the dictionary.Footnote 3 Table 2 presents examples of the
entries in the dictionary. The first column in the dictionary was the syllable’s pinyin, and the second column contained the phonemes with tones attached to the nuclear vowels. The tones
were presented in numbers: 1, 2, 3, and 4, meaning a high-level tone (a.k.a. the first tone), a rising tone (the second tone), a fall-rise tone (the third tone), and a falling tone (the
fourth tone), respectively. For the readers’ information, we also provided one of the possible meanings associated with the pinyin pronunciation in Table 2. The transcripts were also
presented in pinyin, with spaces between each syllable. Table 3 presents a sample of the transcript of a Group 3 type sentence that we used in this experiment. For the readers’ information,
we also provided one of the possible meanings associated with the transcript in Table 3. The output of MFA alignment is annotation files (.textgrid), where phonemes and syllables are
time-aligned. We used the pinyin system in both input and output: Chinese characters were romanized and accompanied by a number to indicate their tones. Figure 2 displays an audio file with
its MFA annotation. When generating MFA alignment output, audio files with “null” (i.e., when the speaker stated that “I do not think the target sentence can be used to express the given
meaning”) and “misread” (i.e., when the speaker recorded a sentence that was different from the given stimuli) were not included. The human alignment output was created upon the MFA
alignment by four well-trained human annotators (also authors of the article) reviewing the boundaries produced by MFA (i.e., boundaries on the “words” tier in Fig. 2) and adjusting
boundaries and interval labels if the MFA-generated boundaries did not match the syllables as intended. We randomly selected 1120 audio files and evaluated the syllable alignment results
that MFA generated, roughly 27.34% of all collected data. Before calculating the accuracy, we first compared the number and the label of intervals in the human alignment and the MFA
alignment on each audio file. If there was any mismatched number or label in the human alignment and the MFA alignment on the same audio file, the entire textgrid files were excluded from
the final comparison. 130 audio files were excluded according to this criterion; in most cases, MFA results have more intervals due to spurious pauses (silent intervals). In the end, the
total number of syllable-level human-aligner pairs that were included in the comparisons is 10,487. To compare the MFA alignment output against human alignment output, we measured the
absolute syllable boundary-time difference for every interval. The comparison results are shown in Table 4. Each cell of the table indicates the group of sentences produced by a specific
speaker (F: female, M: male). _Lab speaker N_ means that the speaker is the _N_th participant who attended the lab recordings. All other recordings were conducted with the speakers’ laptops
or phones. In the average row, the values are presented in milliseconds (ms); the value outside of the parentheses is the average absolute boundary difference and the value within the
paratheses is the standard deviation (SD) for that specific group of data. As we can see from Table 4, MFA produced quite decent syllable-aligned results for Mandarin Chinese, with the
average human-MFA alignment difference being 15.59 ms (SD = 30.41) The average human-MFA syllable-level alignment difference of a group of sentences by a specific speaker ranged from 2.94 ms
to 28.58 ms. Although there were many boundaries that annotators did not need to adjust the MFA-generated ones, there were also many boundaries where annotators needed to make significant
adjustments, yielding high standard deviations in the results. To dig into the causes of the high standard deviations, we further examined the 197 data points where the absolute time
difference is larger than 100 ms. We found that most of these outliers involved the boundaries for _wh_-word (_shuí_, ‘who’), adverb (_yě_, ‘also’) and negation marker (_meí_, ‘not’), and
words with third tones and neutral tones (e.g., _zhě_, _wěi_, _nǎ_, _gěi_, _me_, _le_, _de_, _yǐng_) in the Group 1 and Group 4. We will delve into a detailed discussion to explain why these
certain words can pose challenges for forced alignment in section “Discussion”. Moreover, following the conventional practice of forced aligner evaluation, we chose 25 ms as a threshold to
transform the numerical data into binary data. This binary labeling, “YES” for MFA-human absolute time differences below 25 ms and “NO” otherwise, allowed us to calculate agreement rates. We
then conducted chi-square tests on the binary data to assess statistical significance. The 25 ms proposed by McAuliffe et al. (2017) is the gold-standard threshold used to evaluate the
phone-onset human-aligner difference and has been employed in research on forced aligner evaluation, including Mahr et al. (2021). The evaluation of the data revealed that 73.49% of
human-MFA differences at the syllable level were within 25 ms of the gold standard, indicating a high level of agreement. This rate closely approximates the phone-level agreement rate (77%
within 25 ms) reported by McAuliffe et al. (2017) and is significantly higher than the phone-level agreement rate (64% within 25 ms) reported by Mahr et al. (2021).Footnote 4 The results of
the current test show that MFA can make decent syllable-level alignment for a tonal language like Mandarin, too. Furthermore, MFA is established to correctly align audio files of ambiguous
sentences with underlying phonemic tones but different prosodic markings. Additionally, the average syllable boundary-time difference between humans and MFA for audio files recorded through
phones or laptops (“local recordings”) was 17.02 ms (SD = 31.41). It is numerically higher than the average human-MFA time difference for audio files recorded in a professional recording
booth (“lab recordings”), which was 13.80 ms (SD = 29.02). 71.31% of the human-MFA difference for local recordings was smaller than 25 ms, while 76.20 % of the human-MFA difference for lab
recordings was smaller than 25 ms. There is a significant difference between the local recordings and lab recordings on the 25 ms threshold via a chi-square test (_p_ < .001). This
alignment evaluation shows that the audio input from phones or laptops yields decent MFA syllable-alignment accuracy but is still not as good as the lab recordings, which is consistent with
the findings of Sanker et al. (2021): local recordings are feasible and reliable to get segment boundaries but lab recordings are always better. For all the recordings evaluated in this
test, the overall average human-MFA difference for audio files from female speakers was 15.74 ms (SD: 32.29) with 73.66% of the difference smaller than 25 ms, and the overall average for
male speakers was 15.48 ms (SD: 29.08) with 73.38% of the difference smaller than 25 ms, with no significant effect of gender observed (_p_ > 0.05). EFFICIENCY Previous research mainly
focused on evaluating the alignment accuracy of forced aligners and rarely tested their efficiency. To estimate the MFA-aided syllable-level annotation efficiency, we timed one session of
the syllable-level accuracy evaluation tasks to see how much syllable-level annotation work could be done with MFA in 30 min. The timed assessment was conducted by two of the four expert
human annotators who have been working on the accuracy evaluation. Human annotator X used a Lenovo Legion 5 15IMH05 laptop with Windows operating system, Intel Core i5-10300H CPU @ 2.50 GHz,
and 8GB RAM, while human annotator Y used a MacBook Pro with macOS operating system, 1.4 GHz quad-core Intel Core i5, and 8GB RAM. Both laptops had robust computational and processing
capabilities and were connected to high-speed internet. Before the test, MFA was pre-installed on the annotators' laptops, and the audio files, pronunciation dictionary, and transcripts
were finalized and available in a shared online folder. The annotators were instructed to randomly select a set of audio files from the same speaker, which they had not evaluated, and copy
them to their local working folder to start the timer. Human annotator X chose 32 audio files from Speaker 9 Group 4, with three files labeled as “null” or “misread.” After spending 6 min
copying the required files to a local folder and activating MFA, this annotator generated TextGrid files for the 29 non-null/non-misread audio files, each about three seconds long and
totaling 100 s, and spent 3 min logging annotation notes. In the remaining 21 min, this annotator completed annotations for 14 out of the 30 audio files, finalizing the TextGrid files after
manually adjusting the results generated by MFA. Human annotator Y selected 48 audio files from Speaker 9 Group 1, with no files labeled as “null” or “misread.” After spending 4 min copying
the required files to a local folder and activating MFA, this annotator generated TextGrid files for all 48 audio files, each between two and three seconds long and totaling 131 s, and spent
3 min logging annotation notes. In the remaining 23 min, this annotator finalized annotations for 14 out of the 48 audio files. It is important to note that the results of this efficiency
test depict a relatively optimal scenario, given that the two expert human annotators had prior experience with Praat and MFA as well as the MFA-aided annotation workflow, and the laptops
utilized had sufficient computational and processing capabilities. Nevertheless, as we have seen, a significant amount of time and resources are still saved for speech researchers with the
help of MFA. According to the current efficiency test, MFA-aided annotation took about 30 to 40 min to complete annotation with both phone-level and syllable-level information for a
1-min-long recording. In contrast, literature reported that manual annotation at the phone level can take up to 13 h for a 1-min recording, which is 800 times the duration of the audio
(Goldman, 2011; Schiel et al., 2012: 111). PHRASE-BY-PHRASE ALIGNMENT Prosodic research often focuses on phrase-level intonation and pitch contours. Therefore, the annotation of audio files
should include phrase boundaries. With the help of MFA, the tedious manual annotation work for prosodic research can be significantly simplified. Human annotators do not need to start by
creating an empty annotation file (.textgrid) and draw boundary lines for phrases one by one. Instead, human annotators can take the syllable-level annotation like the one in Fig. 2 as a
starting point and make two steps of small adjustments: first, change selected syllable boundaries to phrase-level boundaries, and second, change the labels at the words-tier to linguistics
phrase labels that fit the prosody research purpose, such as “subject,” “pause”, and “_wh_.” The final product after this adjustment process is shown in Fig. 3. While the existence of
syllable-level segmentation already simplifies the phrase-level annotation process, can it be further simplified? Can we make MFA generate phrase-level aligned boundaries directly? These
questions motivated us to conduct another test with MFA to see whether it can generate phrase-level boundaries with decent alignment accuracy and efficiency. The definition of phrases in
prosody research depends on the research question and the target of analysis. For example, we can divide the sentence in (1) into three phrases: “pre-_wh_ region,” “_wh_-word,” and
“post-_wh_ region” if the primary focus of the prosodic research is to compare the acoustic properties of the pre-_wh_ region and the post_-wh_ region. Alternatively, (1) can be divided into
four phrases: “subject,” “_wh_,” “adverb,” and “verb-negation-complement” if the prosodic research intends to investigate the adverb and the verb phrase separately in the post-_wh_ region.
In this phrase-level alignment test, we used the latter phrasing format. We expect that MFA can exhibit similar phrase-level performance when the first phrasing format is used. (1) [PRE-_WH_
REGION] [_WH_] [POST-_WH_ REGION] [SUBJECT] [_WH_] [ADVERB] [VERB-NEGATION-COMPLEMENT] _Zhōng.guó-duì_ _shuí_ _yě_ _dǎ-bù-guò_ Chinese-team who also beat-not-complement a.
_wh_-indefinite: (i) ‘The Chinese team can’t beat anyone.’ or (ii) ‘No one can beat the Chinese team.’ b. _wh_-interrogative: (iii) ‘Who is the team that the Chinese team also
can’t beat?’ or (iv) ‘Who is the team that also can’t beat the Chinese team?’ THE FORMAT OF TRANSCRIPTS AND DICTIONARIES The Mandarin Chinese transcripts and pronunciation dictionary used
in section “Syllable-by-syllable” alignment follow a character-by-character (i.e., syllable-by-syllable fashion) fashion instead of a word-by-word fashion. It is due to the fundamental
differences between English and Mandarin: there are no noticeable word boundaries in the Chinese writing system, while one Chinese character normally corresponds to one syllable. To get
phrase-by-phrase-aligned boundaries or at least word-by-word boundaries in Mandarin, we started to experiment with MFA by varying the transcript and dictionary input, testing different
combinations on the audio files that were randomly selected from the dataset. For each combination, we tested audio files from Speaker 1, Speaker 8, and Speaker 12 across different groups of
stimuli. We first tried the combination of a phrase-level transcript (Table 5) and the syllable-level dictionary used in section “Syllable-by-syllable alignment” (Table 2). Phrase-level
transcripts were created manually according to the annotation purposes of our prosody project. For example, since the prosody project aims to analyze the prosodic features of _wh_-phrases,
an ideal annotation product would be to consider a complex _wh_-phrase like _nǎ-gè-duì_ ‘which/any team’ as one unit. As in Table 5, the phrase-level transcripts have an empty space in
between two phrases. However, this kind of transcript and dictionary combination did not produce proper alignments. Figure 4 presents the test results of this combination on an audio file
from Speaker 12, Group 2 recording, which refers to the sentence meaning ‘Wangxin did not send anything to Xufang the day before yesterday’.Footnote 5 Note that the syllable-level dictionary
used in section “Syllable-by-syllable” alignment was generated through the 3500 Commonly Used Chinese Character list. As the MFA tutorial guide also mentioned a way to generate a dictionary
from a transcript, we were wondering if a dictionary generated from a small training set produces different phrase alignment results. So, we generated a syllable-level dictionary based on
the syllable-level transcripts and referred to this dictionary as the “small-set” syllable-level dictionary, to distinguish it from the “big-set” syllable-level dictionary (i.e., the one we
used in section “Syllable-by-syllable alignment”).Footnote 6 The two kinds of syllable-level dictionaries have the same format as in Table 2 but only differ in the size of the dictionary.
However, the combination of the “small-set” syllable-level dictionary and the phrase-level transcript (Table 5) did not produce satisfactory results either. Figure 5 presents the test
results of this combination on the same audio file we used to generate Fig. 4. The unsatisfactory alignment results which are shown in both Figs. 4 and 5 suggest that syllable-level
pronunciation dictionaries are not suitable for phrase-level alignment. Therefore, we switched to phrase-level dictionaries in the following trials. In the next trials, we tested the
combinations of phrase-level dictionaries (Table 6) and phrase-level transcripts (Table 5). When creating the phrase-level dictionaries, we explored two ways: one with each phoneme separated
in the description of pronunciation and another with each syllable separated, as in the first row and second row of Table 6, respectively. Figures 6 and 7 present the test results of these
two dictionaries combined with a phrase-level transcript on the same audio file that was used to generate Figs. 4 and 5. The combination of the phrase-level transcript and the phrase-level
dictionary with phoneme-by-phoneme pronunciation seems to give the best alignment results among all the trials, as in Fig. 6. Therefore, we decided to further explore the potential of using
this combination as the input to MFA for generating phrase-level boundaries for prosodic research. ACCURACY As in the previous assessment described in section “Accuracy”, we took audio files
(.wav files) and their accompanying transcripts as well as pronunciation dictionaries (.txt files) as the input; and excluded audio files with “null” or “misread” labels. The only
difference is that the transcripts and pronunciation dictionaries are both phrase level, in the same fashion as what we saw in the first row of Table 6. Figure 6 is an example of MFA
phrase-level annotation results shown in Praat. We used the same 1120 audio files used in the syllable-level evaluation and evaluated the phrase alignment results that MFA generated, roughly
27.34% of all collected data. Human annotation results were created based on MFA annotation by well-trained human annotators reviewing the boundaries produced by MFA (i.e., boundaries on
the “words” tier in Fig. 6) and adjusting boundaries and interval labels if the MFA-generated boundaries did not match the phrases as intended. We applied the same data trimming process and
criteria to the phrase-level annotation results as we did to the syllable-level annotation results. There were 354 audio files involved with at least one mismatched number or label of
intervals in the human alignment and the MFA alignment; in most cases, MFA results and human results have different numbers of silent intervals. After excluding the files with mismatched
sizes and mismatched labels, the total number of phrase-level human-MFA pairs that were included in the comparisons is 3944. The focus of comparison was the absolute phrase boundary-time
difference of each phrase between the MFA alignment and human annotation. The comparison results are shown in Table 7. The same notational conventions for Table 4 are applied to Table 7. As
we can see from Table 7, MFA produced quite decent phrase-aligned results for Mandarin Chinese, with the average human-MFA alignment difference being 22.49 ms (SD = 38.39) The average
human-MFA phrase-level alignment difference of a group of sentences by a specific speaker ranged from 1.33 ms to 282.11 ms. In line with our observations at the syllable level, the
annotation process also revealed instances where the phrase boundaries generated by the MFA did not require any adjustment by the annotators. However, there was also a portion of instances
where significant adjustments were necessary, resulting in high standard deviations and variations in the average time differences among the results. To understand the reasons for the high
standard deviations and variations, we analyzed 106 data points where the absolute phrase boundary-time difference exceeded 100 ms. Out of these, six data points in Speaker9_Group4_M had
extremely high human-MFA time differences of up to 300–700 ms, which were manually checked and found to be an apparent mistake in MFA. The remaining outliers were primarily related to phrase
boundaries with neutral tones and tone sandhi in Group 1 and Group 4 stimuli. These types of words can be challenging for forced alignment because they often have subtle variations in
pronunciation and timing depending on the surrounding context. Additionally, these types of words may have different prosodic properties, such as pitch and intonation, which can further
complicate the alignment process. We will provide an in-depth discussion of this matter in section “Discussion”'. To determine the level of agreement between the MFA and human
annotators at the phrase level, we followed the same data processing procedure as we did for syllable-level evaluation and transformed the time differences into binary data using a 25 ms
threshold. We found that 65.57% of the human-MFA differences at the phrase level were within 25 ms of the gold standard. It is important to note that the number of human-MFA comparison pairs
is influenced by the complexity of phrase boundaries, which may involve suprasegmental features such as intonation and pitch variations. As such, we cannot directly compare the overall
average phrase alignment accuracy to the overall average syllable alignment accuracy reported in this study and previous studies. However, we can reasonably expect a lower human-MFA
agreement at the phrase level compared to the syllable or phone level. Nevertheless, the observed 65.57% agreement rate at the phrase level is considered a very decent level of agreement,
especially when compared to the phone-level agreement rate (64% within 25 ms) reported by Mahr et al. (2021). Moreover, using MFA still provides great help because creating all the phrase
boundaries manually would take a great amount of time and effort. Instead of starting from scratch, letting MFA create the phrase boundaries automatically and later find and fix any errors
would enhance the annotation efficiency to a great extent, as illustrated in section “Efficiency”. Additionally, we found some influence of the recording quality on the accuracy rate of the
phrase-by-phrase alignment. The overall average phrase boundary-time difference for local recordings was 25.86 ms (SD = 42.48) with 57.48% of the difference smaller than 25 ms. The overall
average phrase boundary-time difference for lab recordings was 16.86 ms (SD = 38.87) with 74.16% of the difference for lab recordings. The local recordings demonstrated significantly lower
phrase alignment accuracy compared to the lab recordings on the 25 ms threshold via a chi-square test (_p_ < 0.001). The results of the phrase-by-phrase alignment analysis present a
sharper contrast between lab recordings and local recordings than what we observed in the syllable-level alignment analysis. This finding further emphasizes that a more professional
recording environment is preferable when researching prosodic phrase boundaries. Among all audio files evaluated in this test, the overall average human-MFA difference for audio files from
female speakers was 17.64 ms (SD: 32.31) with 71.95% of the difference smaller than 25 ms, and the overall average for male speakers was 24.13 ms (SD: 41.85) with 61.20% of the difference
smaller than 25 ms. A significant effect of gender on the MFA accuracy was observed (_p_ < 0.001). The interaction between the gender of the speaker and the alignment accuracy indicates
that phrase-level boundary alignment is noticeably difficult in male speech. Since prosodic boundaries are sensitive to suprasegmental features such as pitch and intensity (Wagner and
Watson, 2010), we conjecture that the detection of prosodic boundaries is challenging when the voice pitch is low. The phrase-by-phrase alignment results suggest that researchers should
choose a more professional recording environment if the research concerns prosodic phrase boundaries. EFFICIENCY To evaluate MFA-aided phrase-level annotation efficiency, we timed one
session of the phrase-level accuracy evaluation tasks to see how much phrase-level annotation work could be done with MFA annotation in 30 min using phrase-level transcripts and
dictionaries. Two well-trained human annotators attended this timed evaluation. They were the same human annotators using the same laptops who participated in the time evaluation for
syllable alignment in section “Efficiency”. Similar to the time evaluation in section “Efficiency”, MFA and required files were prepared before the efficiency test. They were asked to choose
a set of audio files from the same speaker and to start the timer once they began to copy the selected audio files to the working folder. Human annotator X selected the recordings from Lab
Speaker 6, Group 3, where 32 audio files were in the folder with 13 audio files labeled “null” or “misread.” This human annotator spent 8 min copying required files to a local folder,
activating MFA, and using MFA to generate all the TextGrid files for the 19 non-null or non-misread audio files (in total 54 s long with each file being about 3 s long) and 3 min logging
annotation notes. During the remaining 19 min, this human annotator was able to complete annotations for 14 out of the 19 audio files, which means that the TextGrid files were finalized for
these 14 files after human annotators’ manual adjustments to the annotation results generated by MFA. Human annotator Y selected the recordings from Lab Speaker 6, Group 2, where 16 audio
files were in the folder with 0 audio files labeled “null” or “misread.” This human annotator spent 5 min copying required files to a local folder, activating MFA, and using MFA to generate
all the TextGrid files for the 16 non-null or non-misread audio files (in total 50 s long with each file being about 3 s long) and 3 min logging annotation notes. During the remaining 22
min, this human annotator was able to complete annotations for 12 out of the 16 audio files. Although we cannot make a direct comparison regarding efficiency between syllable-alignment and
phrase-alignment, the two human annotators both reported that they thought a phrase-level dictionary and transcript was better than a syllable-level dictionary and transcript for improving
annotation efficiency for a prosody project that requires phrase-by-phrase annotation. Human annotators’ feedback makes us optimistic about the application of MFA with a phrase-level
transcript and dictionary in Mandarin prosody research. DISCUSSION We evaluated the MFA-generated syllable-level results and phrase-level results manually to compare the human-MFA annotation
difference, as reported in section “Syllable-by-syllable alignment”. While the results suggested that using MFA would make the annotation task much more effective and efficient, we found
that it showed less satisfactory performance when complex or non-salient acoustic features were involved. The most common error for MFA’s syllable-level alignment was found for syllables
with a third tone, such as _zhě_ (‘person’)_, wěi_ (‘person given name’)_, nǎ_ (‘which’)_, yě_ (‘also’)_, gěi_ (‘for’)_, diǎn_ (‘a little’), or those with a neutral tone, such as _le_ (an
aspect marker in Mandarin) and _de_ (a complement marker). This finding is compatible with the unique acoustic features of third tones and neutral tones. Among the four basic tones in
Mandarin, the third tone is different from the other three tones because it is internally a combination of falling-rising tones. Moreover, the third tone is often realized with a rising tone
before another syllable with a third tone due to the tone change process called “third tone sandhi.” The acoustic characteristics of the third tone and tone sandhi are considerably complex,
making the alignment performance less accurate than others. The characteristic of a neutral tone is that it is “de-focused”, meaning that you do not have to put extra stress on the syllable
but only need to give it the same amount of stress as what has been given to the preceding syllable. Neutral tones are also often shorter than the other tones. These acoustic features of
neutral tones (i.e., short and non-salient) can be the primary reason why MFA often shows alignment errors on the boundaries of syllables with neutral tones. The most common error for MFA’s
phrase-level alignment was found when phrases contained functional words. Functional words are words that have a grammatical purpose, such as classifiers (e.g., _wèi, gè_), negation markers
(e.g., _méi, bù_), adverbs (e.g., _yě_), determiners (e.g., _diǎn_), prepositions (e.g., _gěi_), aspect markers (e.g., _guò_), and adverbial clause markers (e.g., _rúguǒ_, _dehuà_). In
Mandarin, frequently used functional words with regular tones often have reduced pronunciations in speech production. Monosyllabic functional words, such as _yě_ ‘also’ typically have only
one syllable and that syllable is often unstressed and phonetically reduced. Similarly, the second syllable in disyllabic functional words, such as _rúguǒ_ ‘if’, is often pronounced with
reduced stress and phonetic prominence (Lai et al., 2010; Yang, 2010, Třísková, 2016). Syllables with neutral tones and phrases with functional words share the same acoustic feature: being
de-stressed. Therefore, MFA does not perform well in these de-stressed parts for both syllable-level and phrase-level alignment. The finding calls for improvement of forced aligners,
including MFA concerning alignments for de-stressed speech. Pronunciation variations and _er_-suffixation (also known as “Erhua” in the literature) are two other challenges for forced
alignment at both the syllable and phrase levels. Examples of pronunciation variations include the _wh_-words _shuí_ (‘who’) and _nǎ_ (‘which’) are sometimes pronounced as _sheí_ and _něi_
in speech production due to dialectal influence. We observed that MFA shows lower accuracy for audio files where speakers pronounced the words with such variants. _Er_-suffixation refers to
a phonological resyllabification in Mandarin. In the data we evaluated, the syllable _er_ and the syllable _diǎn_ (from Group 2 Stimuli) are often combined into one syllable in speech
production by speakers. This phonological resyllabification process not only changes the syllable boundary but also influences the tone and phonetic realization of the _er_-suffixed forms
(Huang, 2010). What makes the _er_-suffixation process more complicated is that it may be implemented differently in dialects of Mandarin (Jiang et al., 2019). This finding further
underscores the necessity of forced aligners, including MFA, to take into account dialectal influences and speech variations among speakers. By recognizing and accounting for these
variations, forced aligners can more accurately align speech signals with their corresponding text and improve the overall performance of automatic speech recognition systems. CONCLUSION
This paper presents the first detailed evaluation reports of MFA regarding its alignment accuracy and efficiency at both the syllable level and phrase level for prosody research in Mandarin
Chinese, a tonal language. In both syllable-alignment and phrase-alignment tasks, the average differences between human annotators and MFA were smaller than the gold standard (25 ms).
Furthermore, MFA-aided annotation by human transcribers was at least 20 times faster than the manual annotation that has been previously reported. Although MFA showed less accuracy for the
non-salient acoustic features, speech with non-standard pronunciations, and audio files with lower quality, its decent alignment accuracy and high efficiency indicate that it would be useful
for simplifying the annotation process in prosody research, even when dealing with tonal languages like Mandarin. The recording quality significantly affects both MFA’s syllable-level and
phrase-level alignment, emphasizing the need to control audio quality in prosody research when using MFA. Additionally, a gender effect was observed in MFA’s phrase-level alignment,
highlighting the importance of addressing gender effects in prosody research. Our study proposes a new workflow for conducting prosodic research in tonal languages. This approach involves
using MFA for phrase-level annotation, followed by necessary adjustments made by human annotators. By adopting this workflow, researchers can save considerable time and resources that would
otherwise be required for manual human annotation. This will have a significant impact on the field of prosodic research, as it will enable researchers to investigate the role of prosody in
tonal languages more efficiently and effectively. The finding that de-stressed words and phrases, as well as pronunciation variations, pose challenges for MFA provides a reference for
improving forced aligners. With continuous advancements in forced aligner technology, we expect a lower human-MFA syllable-/phrase-boundary difference and a higher percentage of the
differences being smaller than the gold standard. As we were finalizing our paper, MFA released version 2.0 of its acoustic model, along with a Mandarin (Erhua) pronunciation dictionary. The
new dictionary includes additional pronunciations, such as reduced variants commonly found in spontaneous speech, where segments or syllables are deleted. This update is expected to improve
the performance of MFA, particularly in areas such as _er_-suffixation. We look forward to testing this conjecture in follow-up studies and expanding the current research into other tonal
languages, thereby offering a systematic and comprehensive reference for the advancements in forced aligner technology. DATA AVAILABILITY A complete list of target sentences, and the data
for syllable-level, and phrase-level comparisons are available at the Dataverse repository: https://doi.org/10.7910/DVN/EV4KAN. The audio files and annotated text-grid files generated during
the current study are not publicly available due to them containing information that could compromise research participant privacy and consent but are available from the corresponding
author on reasonable request. NOTES * The MFA tool we used in the paper was MFA version 1.0. It contains a pre-trained grapheme-to-phoneme conversion (G2P) model for Mandarin Chinese that
supports both characters and pinyin, as well as a pre-trained acoustic model for Mandarin. It contains an example of a Mandarin pronunciation dictionary but not a full-scale, ready-to-use
one; thus, we created our own pronunciation dictionary, as explained in section “Evaluations”, following the MFA’s user guide. At the time we were writing up the paper, MFA released updates
for version 2.0 in June 2022. According to the latest release of MFA G2P models, there is no Mandarin G2P 2.0 model available at this moment, while the Mandarin MFA dictionary, version 2.0
version, and the Mandarin MFA acoustic model, version 2.0. have been released. * For the non-lab recordings, we instructed the speakers to record the sentences in a quiet room, without
specifying any recording parameters for their phones or laptops. The iPhone models used by Speakers 1, 3, 4, 6, 7, 8, 11, 12, and 15 included the iPhone 6 s, iPhone 11, iPhone 12, iPhone X,
iPhone SE 2, and iPhone 12 pro. Speaker 2 and 14, respectively, used Huawei Mate 20 and Samsung S20 phones, while Speaker 9 and 13 used Lenovo laptops for recordings. All of the devices used
by non-lab speakers had built-in microphones that produced high-quality audio files. The lab recordings were made in a sound-proof room using an Audio-Technica AT4050 microphone and a Denon
Recorder (DN-700r). By default, the recorder produces audio files in MP3 format at 128kbps with 44.1 kHz stereo sampling rate. When evaluating the MFA results, we did not distinguish
between mobile phone and laptop recordings as the non-lab recordings we collected were mostly mobile phone recordings. While using audio files with varying quality can help assess how well
MFA can handle such files, we acknowledge that different audio signal characteristics can yield different results. In future studies, we plan to employ a fully controlled experiment design
with balanced data to thoroughly examine how audio signal characteristics affect forced aligner accuracy and efficiency. * This file with brief English instructions can be accessed at
https://lingua.mtsu.edu/chinese-computing/statistics/char/listchangyong.php. * The existing MFA evaluation research focuses on the phone-onset difference, with no direct syllable-boundary
evaluation results that we can use as a reference. However, syllable-boundary can be more complicated than phone-onset, as it may involve syllable-level acoustics features like stress. With
that being said, the results of the current test are very promising. * The label “spn” in MFA is used for modeling unknown words. However, we observed that when MFA encounters a sound that
it cannot recognize accurately, it assigns the “spn” label to the corresponding interval. For example, although the syllable _de_ with a neutral tone in Mandarin is present in the transcript
and dictionary input, MFA often labels the corresponding phonemes as “spn.” * The usage of MFA to generate the dictionary does not involve training the acoustic model. Instead, we leverage
the pre-trained g2p model in MFA for this purpose. (https://montreal-forced-aligner.readthedocs.io/en/latest/first_steps/example.html#dict-generating-example) REFERENCES * Boersma P, Weenink
D (2021) Praat: doing phonetics by computer [Computer program], Version 6.1.53, retrieved 23 Sept 2021 from. https://www.praat.org * DiCanio C, Nam H, Whalen DH, Bunnell HT, Amith JD,
García RC (2013) Using automatic alignment to analyze endangered language data: testing the viability of untrained alignment. J Acoust Soc Am 134(3):2235–2246.
https://doi.org/10.1121/1.4816491 Article ADS PubMed PubMed Central Google Scholar * Goldman JP (2011) EasyAlign: an automatic phonetic alignment tool under Praat. Proceedings of the
12th Annual Conference of the International Speech Communication Association, Florence, Italy, pp. 3233–3236. August 28–31, 2011 Google Scholar * Gonzalez S, Grama J, Travis C (2020).
Comparing the performance of forced aligners used in sociophonetic research. Linguist Vanguard. 5. https://doi.org/10.1515/lingvan-2019-0058 * Gorman K, Howell J, Wagner M (2011)
Prosodylab-aligner: a tool for forced alignment of laboratory speech. Can Acoust 39:192–193 Google Scholar * Huang T (2010) _Er_-suffixation in Chinese monophthongs: phonological analysis
and phonetic data. In: Clemens LaurenE, Liu Chi-MingLouis eds Proceedings of the 22rd North American Conference on Chinese Linguistics (NACCL-22) and the 18th International Conference on
Chinese Linguistics (IACL-18). Harvard University, Cambridge, MA, pp. 331–344 Google Scholar * Hosom JP (2009) Speaker-independent phoneme alignment using transition-dependent states.
Speech Commun 51:352–368 Article PubMed PubMed Central Google Scholar * Jiang S, Chang Y, Hsieh F (2019) An EMA study of Er-suffixation in Northeastern Mandarin monophthongs. In: Calhoun
S, Escudero P, Tabain M, Warren P (eds.) Proceedings of the 19th International Congress of Phonetic Sciences. Australasian Speech Science and Technology Association Inc., Melbourne,
Australia, pp. 2149–2153 Google Scholar * Lai C, Sui Y, Yuan J (2010) A corpus study of the prosody of polysyllabic words in Mandarin Chinese. Speech Prosody 2010 100457:1–4.
http://www.sprosig.org/sp2010/papers/100457.pdf. Accessed on 9 Jul 2023 * Liu S, Sóskuthy M (2022) Evaluating the accuracy of forced alignment across Mandarin varieties. The Journal of the
Acoustical Society of America 151:A131. https://doi.org/10.1121/10.0010882 Article ADS Google Scholar * MacKenzie LTurton D (2020) Assessing the accuracy of existing forced alignment
software on varieties of British English. Linguist Vanguard 6(s1):20180061. https://doi.org/10.1515/lingvan-2018-0061 * Mahr TJ, Berisha V, Kawabata K, Liss J, Hustad KC (2021) Performance
of forced-alignment algorithms on children’s speech. Journal of speech, language, and hearing research JSLHR 64(6S):2213–2222. https://doi.org/10.1044/2020_JSLHR-20-00268 Article PubMed
PubMed Central Google Scholar * McAuliffe M, Socolof M, Mihuc S, Wagner M, Sonderegger, M (2017) Montreal Forced Aligner: trainable text-speech alignment using Kaldi. Proceedings of the
18th Conference of the International Speech Communication Association, 498–502. https://doi.org/10.21437/Interspeech.2017-1386 * McAuliffe M (2021) Update on Montreal Forced Aligner
performance. https://memcauliffe.com/update-on-montreal-forced-aligner-performance.html. Accessed 8 May 2022 * Pettarin A (2018) GitHub-pettarin/forced-alignment-tools: a collection of links
and notes on forced alignment tools. https://github.com/pettarin/forced-alignment-tools. Accessed 8 May 2022 * Sanker C, Babinski S, Burns R, Evans M, Johns J, Kim J, Smith S, Weber N,
Bowern C (2021) (Don't) try this at home! The effects of recording devices and software on phonetic analysis. Language 97(4):e360–e382. https://doi.org/10.1353/lan.2021.0075 Article
Google Scholar * Schiel F, Draxler C, Baumann A, Ellbogen T, Steffen A (2012) The production of speech corpora, version 2.5. https://epub.ub.uni-muenchen.de/13693/1/schiel_13693.pdf.
Accessed 5 Sept 2022 * Sella V (2018) Automatic phonological transcription using forced alignment: FAVE toolkit performance on four non-standard varieties of English. Bachelor’s degree
Project English Linguistics. Department of English. Stockholms University * Třísková H (2016) De-stressed words in Mandarin: drawing parallel with English. In: Hongyin Tao (eds.) Integrating
Chinese linguistic research and language teaching and learning. 121–144. John Benjamins Publishing Company. https://doi.org/10.1075/scld.7.07tri * Wagner M, Watson DG (2010) Experimental
and theoretical advances in prosody: a review. Lang Cogn Process 25(7-9):905–945 Article PubMed PubMed Central Google Scholar * Wu H, Yun J (2022) Prosodic disambiguation of
_Wh_-indeterminates in Mandarin Chinese. Manuscript * Yang L (2010) Putonghua shuangyinjie ci de zhongyin moshi yu cipin guanxi (The relationship between the stress pattern and word
frequency of disyllabic words in Mandarin). In: Clemens LaurenE, Liu Chi-MingLouis eds. Proceedings of the 22rd North American Conference on Chinese Linguistics (NACCL-22) and the 18th
International Conference on Chinese Linguistics (IACL-18). Harvard University, Cambridge, MA, pp. 274–282 Google Scholar * Yuan J, Ryant N, Liberman M (2014) Automatic phonetic segmentation
in Mandarin Chinese: boundary models, glottal features and tone. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2539–2543,
https://doi.org/10.1109/ICASSP.2014.6854058 * Yuan J, Liberman MY (2015) Investigating consonant reduction in Mandarin Chinese with improved forced alignment. Proc Interspeech
2015:2675–2678. https://doi.org/10.21437/Interspeech.2015-401 Article Google Scholar * Yuan J, Lai W, Cieri C, Liberman MY (2018) Using forced alignment for phonetics research. In: Huang
C-R, Hsieh S-K, Jin p (eds) Chinese language resources and processing: text, speech and language technology. Springer. Springer.
http://languagelog.ldc.upenn.edu/myl/ForcedAlignment_Final_edited.pdf. Accessed on 15 Jun 2022 Google Scholar Download references ACKNOWLEDGEMENTS This study is supported by the Faculty
Development Fund from the School of Modern Languages and the 2022 Summer Professional Development from Ivan Allen College of Liberal Arts, both awarded to the first author at Georgia
Institute of Technology. The authors are grateful to Hossep Dolatian and Jamilläh Rodriguez for their valuable comments and suggestions. The authors thank all participants who took part in
this study. The first author would also like to thank Zhaoran Ma for helping with recruiting participants, Alison Valk for helping with professional audio recording equipment setup and space
reservations. Any remaining errors are solely the responsibility of the authors. AUTHOR INFORMATION AUTHORS AND AFFILIATIONS * Georgia Institute of Technology, Atlanta, GA, USA Hongchen Wu,
Xiang Li, Huiyi Huang & Chuandong Liu * Stony Brook University, Stony Brook, NY, USA Jiwon Yun Authors * Hongchen Wu View author publications You can also search for this author
inPubMed Google Scholar * Jiwon Yun View author publications You can also search for this author inPubMed Google Scholar * Xiang Li View author publications You can also search for this
author inPubMed Google Scholar * Huiyi Huang View author publications You can also search for this author inPubMed Google Scholar * Chuandong Liu View author publications You can also search
for this author inPubMed Google Scholar CONTRIBUTIONS HW: conception and design of the study; funding acquisition; project administration; data collection, annotation, analysis, and
interpretation; drafting and revising the manuscript. JY: data analysis and interpretation; checking and revising the manuscript. XL: data annotation; forced aligner experimenting and
documentation; drafting the section for the format of transcripts and dictionaries. HH: data annotation; efficiency test documentation; drafting the tables for accuracy rates. CL: data
annotation; efficiency test documentation. All authors approved the final manuscript to be published. All authors agreed to be accountable for all aspects of the work in ensuring that
questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved. CORRESPONDING AUTHOR Correspondence to Jiwon Yun. ETHICS DECLARATIONS
COMPETING INTERESTS The authors declare no competing interests. ETHICAL APPROVAL The questionnaire and methodology for this study were approved by the Institutional Review Board of Stony
Brook University (IRB2021-00358), and the Institutional Review Board of Georgia Institute of Technology (H21340) as minimal risk research qualified for exemption status. INFORMED CONSENT
Informed consent was obtained from all participants to contribute the audio files and have their recordings to be analyzed and presented in an anonymous way in an academic venue. All the
data from this study is saved on a password-protected share drive that only the study team has full access to. ADDITIONAL INFORMATION PUBLISHER’S NOTE Springer Nature remains neutral with
regard to jurisdictional claims in published maps and institutional affiliations. RIGHTS AND PERMISSIONS OPEN ACCESS This article is licensed under a Creative Commons Attribution 4.0
International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the
source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative
Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by
statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit
http://creativecommons.org/licenses/by/4.0/. Reprints and permissions ABOUT THIS ARTICLE CITE THIS ARTICLE Wu, H., Yun, J., Li, X. _et al._ Using a forced aligner for prosody research.
_Humanit Soc Sci Commun_ 10, 429 (2023). https://doi.org/10.1057/s41599-023-01931-4 Download citation * Received: 01 December 2022 * Accepted: 11 July 2023 * Published: 19 July 2023 * DOI:
https://doi.org/10.1057/s41599-023-01931-4 SHARE THIS ARTICLE Anyone you share the following link with will be able to read this content: Get shareable link Sorry, a shareable link is not
currently available for this article. Copy to clipboard Provided by the Springer Nature SharedIt content-sharing initiative